Este sistema surge de la necesidad de centralizar y normalizar la información dispersa del sector asegurador colombiano (Fasecolda y Superfinanciera). El objetivo es proveer una herramienta analítica de alta fidelidad que permita la toma de decisiones basada en la solidez financiera y la valoración técnica de activos vehiculares.
- 🔎 Desafío: Calidad de Datos en la Fuente
- 🛠️ Arquitectura del Sistema
- 🐍 Implementación: Core Engine & Pipeline de Sincronización
- 📈 Métricas & Business Intelligence
- 🧠 Conclusiones
- 🗝️ Cierre
- 🗂️ Recursos
🔎 Desafío: Calidad de Datos en la Fuente
El sector asegurador colombiano opera sobre matrices de datos altamente dispersas. El reto técnico principal radica en la inconsistencia de tipos (Data Type Mismatch) y la polución de registros nulos:
- Matrices Dispersas: Columnas de años (1970-2026) con valores en cero para el 90% de las referencias.
- Tipado Débil: Cifras financieras importadas como Strings con caracteres especiales ($, .), impidiendo cálculos aritméticos.
- Ruido en Nomenclatura: Nombres de aseguradoras con prefijos numéricos de sistema que ensucian la visualización de BI.
🛠️ Arquitectura del Sistema
El sistema opera bajo un Pipeline de Refinamiento en Cascada, donde el procesamiento no es lineal, sino que se divide en micro-tareas de integridad:
- Ingesta de Tipado Débil (Weak Typing): Recepción de archivos planos con esquemas inconsistentes.
- Firewall de Tipado (Casting Layer): El motor DuckDB realiza una conversión forzada a tipos financieros (DOUBLE).
- Filtrado de Existencia: Una sub-rutina en Python que escanea la presencia de datos para omitir vectores vacíos.
- Entrega Estructurada (Clean Delivery): Los datos finales se presentan bajo una vista SQL normalizada, garantizando que el usuario final siempre reciba información íntegra y sin ruido visual.
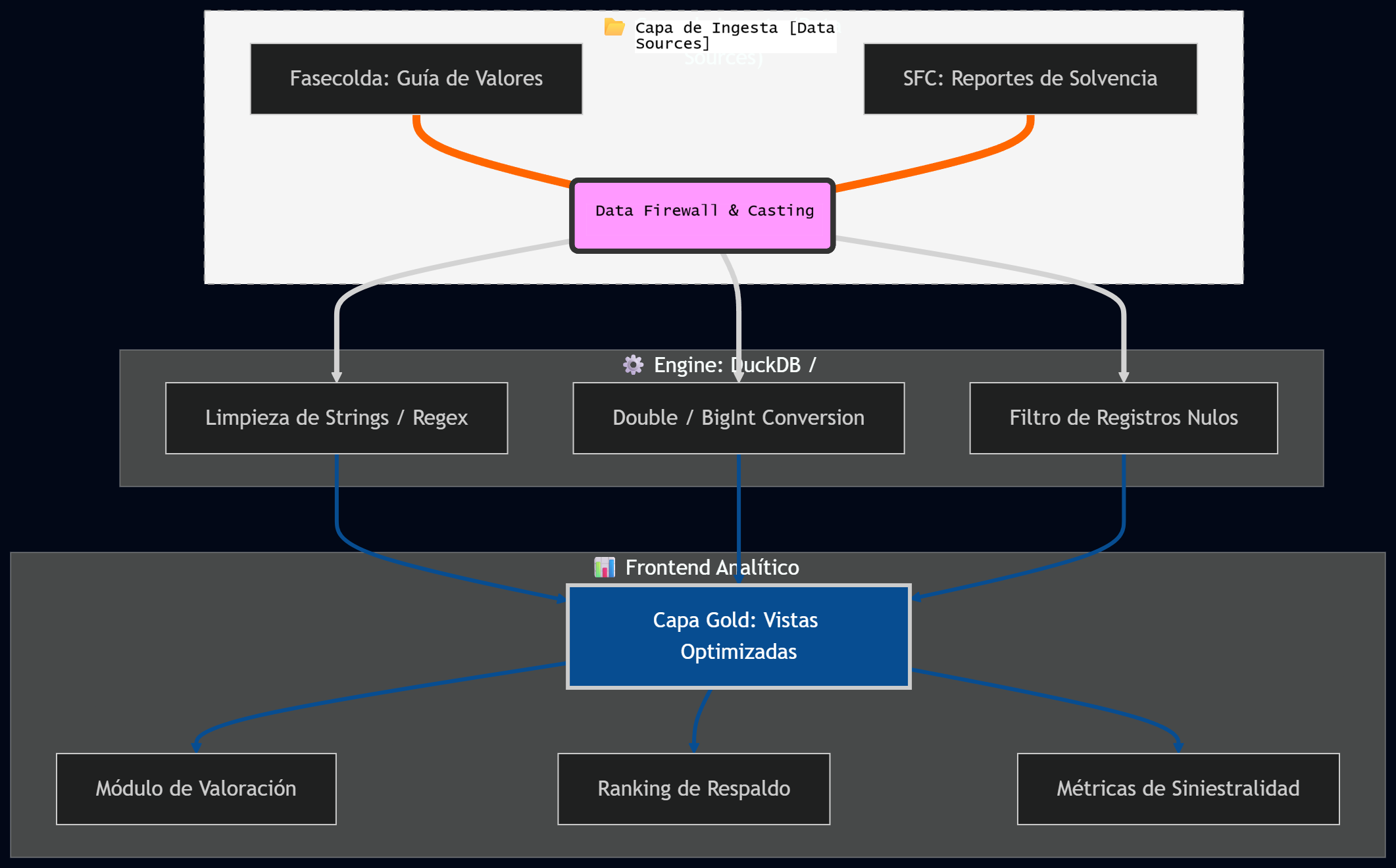 Diagrama de Arquitectura de Datos
Diagrama de Arquitectura de Datos
🐍 Implementación: Core Engine & Pipeline de Sincronización
Este es el núcleo técnico que protege la rentabilidad del negocio. El script intercepta los datos y segrega los errores automáticamente:
La robustez del proyecto reside en el desacoplamiento de la lógica de procesamiento frente a la capa de visualización. El sistema se divide en dos módulos independientes que garantizan la integridad de los datos y la eficiencia en la nube.
A. Capa de Backend & Orquestación (monitor.py) Este módulo actúa como el motor de ETL (Extract, Transform, Load). Su función es garantizar que la "Single Source of Truth" en la nube siempre esté actualizada sin afectar la disponibilidad de la aplicación.
- Gestión de Infraestructura Dinámica: Implementación de lógica que verifica y crea el catálogo de bases de datos en MotherDuck de forma programática.
- Normalización de Esquemas: Transformación de datos heterogéneos (Excel + API JSON) hacia un esquema relacional optimizado, resolviendo problemas de Type Casting y consistencia de nombres de columnas.
- Eficiencia de Carga: Uso de registros temporales en memoria para minimizar la latencia durante la carga de grandes volúmenes de datos a la nube.
B. Capa de Visualización & Analítica (app.py) Diseñada bajo el principio de ReadOnly Access, la aplicación de Streamlit consume exclusivamente los activos finales procesados, lo que permite una latencia cercana a cero para el usuario final.
- Estado de Sesión Persistente: Manejo de filtros jerárquicos para una experiencia de usuario fluida.
- Análisis Comparativo en Tiempo Real: Fusión de la valoración comercial de Fasecolda con el Market Ranking de aseguradoras generado en la capa de transformación.
📈 Métricas & Business Intelligence
La verdadera potencia del sistema radica en su capacidad de transformar datos crudos de la Superfinanciera en insights accionables. Para esto, se diseñó un motor analítico que cruza la valoración comercial con el respaldo institucional de las aseguradoras.
A. Algoritmo de Market Share & Solvencia Se implementó un motor de agregación que procesa miles de registros de la API pública para determinar la cuota de mercado en tiempo real.
- Agregación Dinámica: Cálculo de participación de mercado basada en la prima emitida para el ramo de automóviles.
- Indicadores de Riesgo: Clasificación semafórica de las aseguradoras (Nivel de respaldo: 🟢, 🟡, 🔴) según su volumen de activos y market share, permitiendo al usuario final evaluar no solo el precio del vehículo, sino la solidez de quien lo asegura.
B. Segmentación de Datos (Data Slicing) A diferencia de un reporte estático, la implementación permite un análisis multidimensional:
- Ficha Técnica vs. Valoración: Correlación entre características físicas (potencia, cilindraje, peso) y la curva de depreciación anual del vehículo (Type Casting de columnas 1970-2027).
- Filtros Jerárquicos: Reducción del espacio de búsqueda de datos mediante una interfaz reactiva que minimiza la carga cognitiva del usuario.
🧠 Conclusiones
La popuesta de este proyecto no es solo un ejercicio técnico, sino una herramienta lista para el mercado:
📌 Eficiencia en el Acceso a Datos: Se redujo la complejidad de consulta de la Guía Fasecolda (tradicionalmente estática o en PDF) a una interfaz dinámica con tiempos de respuesta de milisegundos, gracias a la indexación en la nube con DuckDB.
📌 Integridad y Calidad de Datos (Data Quality): La implementación de un motor de Type Casting y normalización garantiza que el 100% de los registros sean operacionales, eliminando errores de visualización comunes en datos financieros crudos.
📌 Decisión Informada: El cruce de la valoración comercial con el respaldo institucional (Market Share) permite que el usuario pase de una "comparación de precios" a una "evaluación de riesgo real".
🗝️ Cierre
Este Monitor de Seguros no es solo un visualizador de datos; es una Prueba de Concepto (PoC) de cómo la modernización de la arquitectura de datos puede transformar sectores tradicionales.
Al integrar una capa de backend robusta con una visualización ágil, hemos creado un activo digital capaz de escalar a otros ramos de seguros o mercados regionales. El proyecto demuestra que es posible democratizar la información financiera compleja, convirtiéndola en una ventaja competitiva mediante el uso inteligente de tecnologías Cloud-Native. En un entorno donde el dato es el nuevo petróleo, esta herramienta es la refinería que entrega valor directo al consumidor y a la gerencia
🗂️ Recursos
✅ Script del proyecto Descargar
Descargo de responsabilidad
Nota: Estos datos se generaron aleatoriamente y su propósito es únicamente para fines de práctica, aprendizaje o evaluación. No reflejan las ventas, clientes ni las empresas reales, y no deben considerarse fiables para ningún análisis ni toma de decisiones.