Este proyecto establece una infraestructura de Gobierno de Datos que garantiza la integridad financiera. No es solo un dashboard; es un mecanismo de control preventivo que asegura que el 100% de las decisiones de pricing se basen en datos auditados y libres de ruido contable.
- 🔎 Desafío: Calidad de Datos en la Fuente
- 🛠️ Arquitectura del Sistema
- 🐍 Implementación del Firewall (Python)
- 📈 Métricas de Product Ops
- 🧠 Conclusiones
- 🗝️ Cierre
- 🗂️ Recursos
🔎 Desafío: Calidad de Datos en la Fuente
Este proyecto evolucionó de un análisis de ventas tradicional a una solución de Ingeniería de Datos. Durante la fase de due diligence de datos, identifiqué una vulnerabilidad crítica en la fuente: la ausencia de validaciones de lógica de negocio en el origen.
Identificar esta 'fuga de verdad' fue el catalizador para diseñar un pipeline que antepone la calidad al volumen.
Para un Product Ops Analyst, procesar estos datos significaría entregar reportes financieros falsos. Por ello, implementé una arquitectura que actúa como un filtro de calidad antes de cualquier análisis.
🛠️ Arquitectura del Sistema
Diseñé un pipeline híbrido para garantizar la integridad:
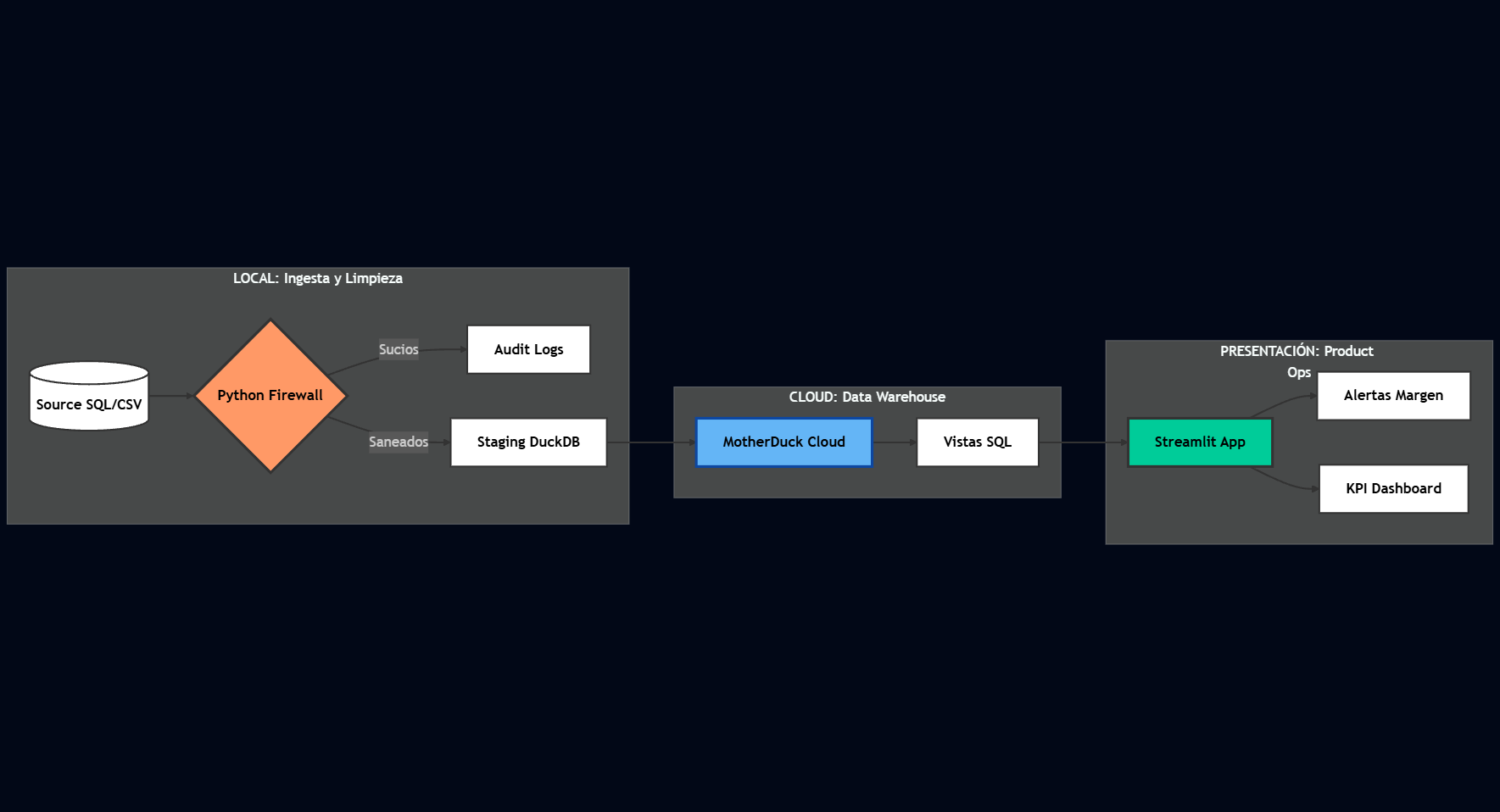
- Ingesta: Extracción desde SQLite a DuckDB.
-
Firewall (Python): Validación de márgenes y consistencia contable.
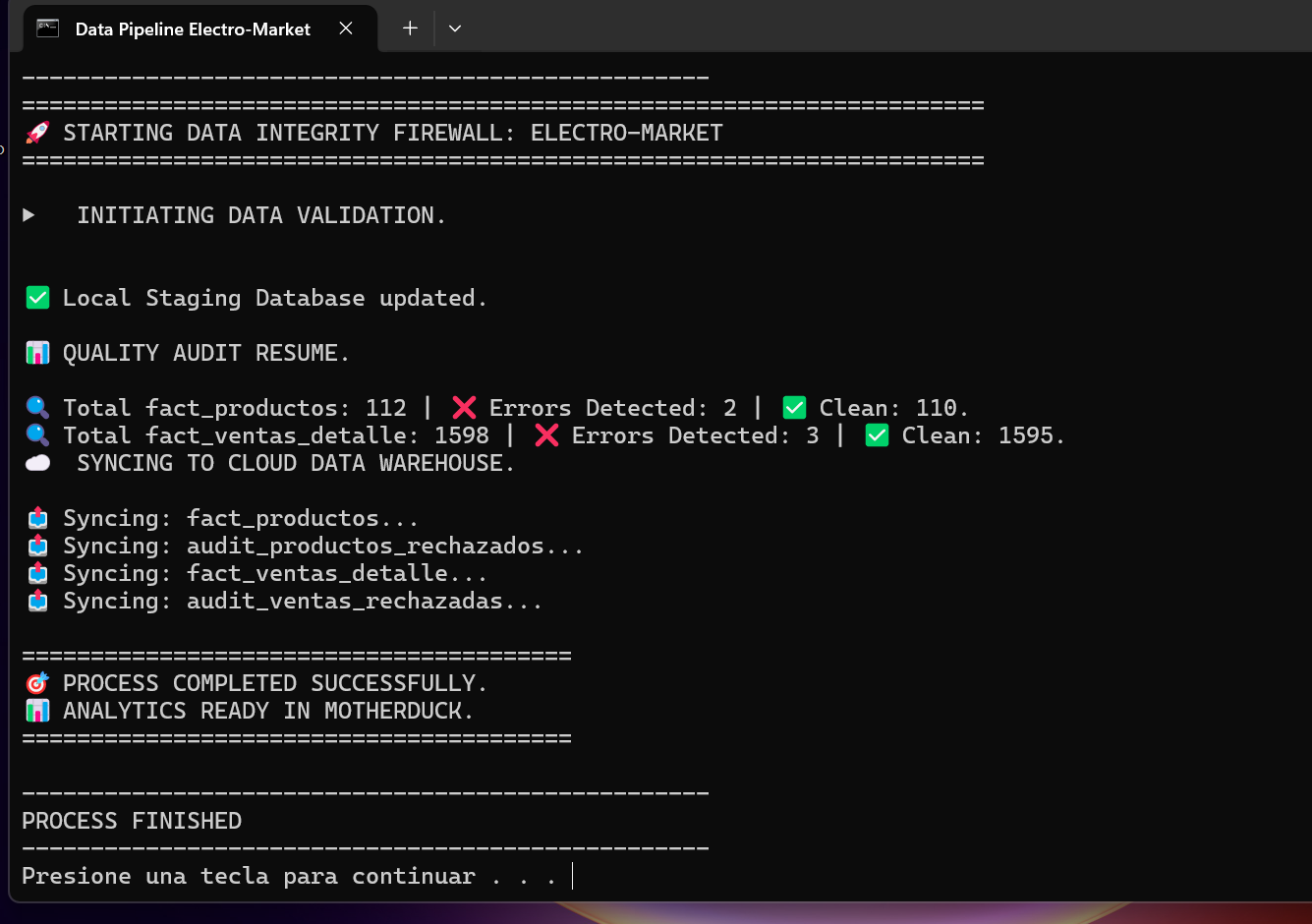 Consola de ejecución: Validación de 112 productos y 1,598 ventas con detección de anomalías.
Consola de ejecución: Validación de 112 productos y 1,598 ventas con detección de anomalías. -
Staging (DuckDB): Almacenamiento local de datos limpios y auditoría de errores.
-
Analytics Cloud (MotherDuck): Sincronización de datos validados para visualización.
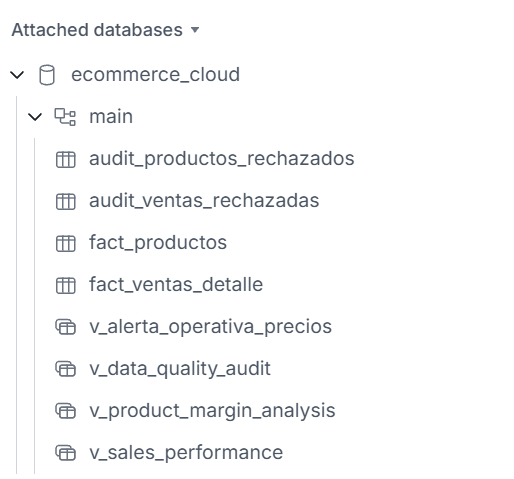 Organización de la base de datos híbrida: Staging local en DuckDB y Warehouse final en MotherDuck.
Organización de la base de datos híbrida: Staging local en DuckDB y Warehouse final en MotherDuck.
🐍 Implementación del Firewall (Python)
Este es el núcleo técnico que protege la rentabilidad del negocio. El script intercepta los datos y segrega los errores automáticamente:
import pandas as pd
def run_firewall_products(df):
"""
Detecta 'Fuga de Capital':
Identifica productos donde el precio es menor o igual al costo.
"""
mask_error_precio = df['proPrecio'] <= df['proCosto']
limpios = df[~mask_error_precio].copy()
rechazados = df[mask_error_precio].copy()
return limpios, rechazados
def run_firewall_sales(df_detalle):
"""
Validación Contable:
Asegura que Unidad * Precio sea igual al Subtotal reportado.
"""
df_detalle['subtotal_calc'] = df_detalle['unidad'] * df_detalle['precio_unitario']
mask_error = (df_detalle['subtotal'] - df_detalle['subtotal_calc']).abs() > 0.01
ventas_limpias = df_detalle[~mask_error].copy()
ventas_rechazadas = df_detalle[mask_error].copy()
return ventas_limpias, ventas_rechazadas
📈 Métricas de Product Ops
Al limpiar los datos, las métricas pasaron de ser "ruido" a ser insights accionables:
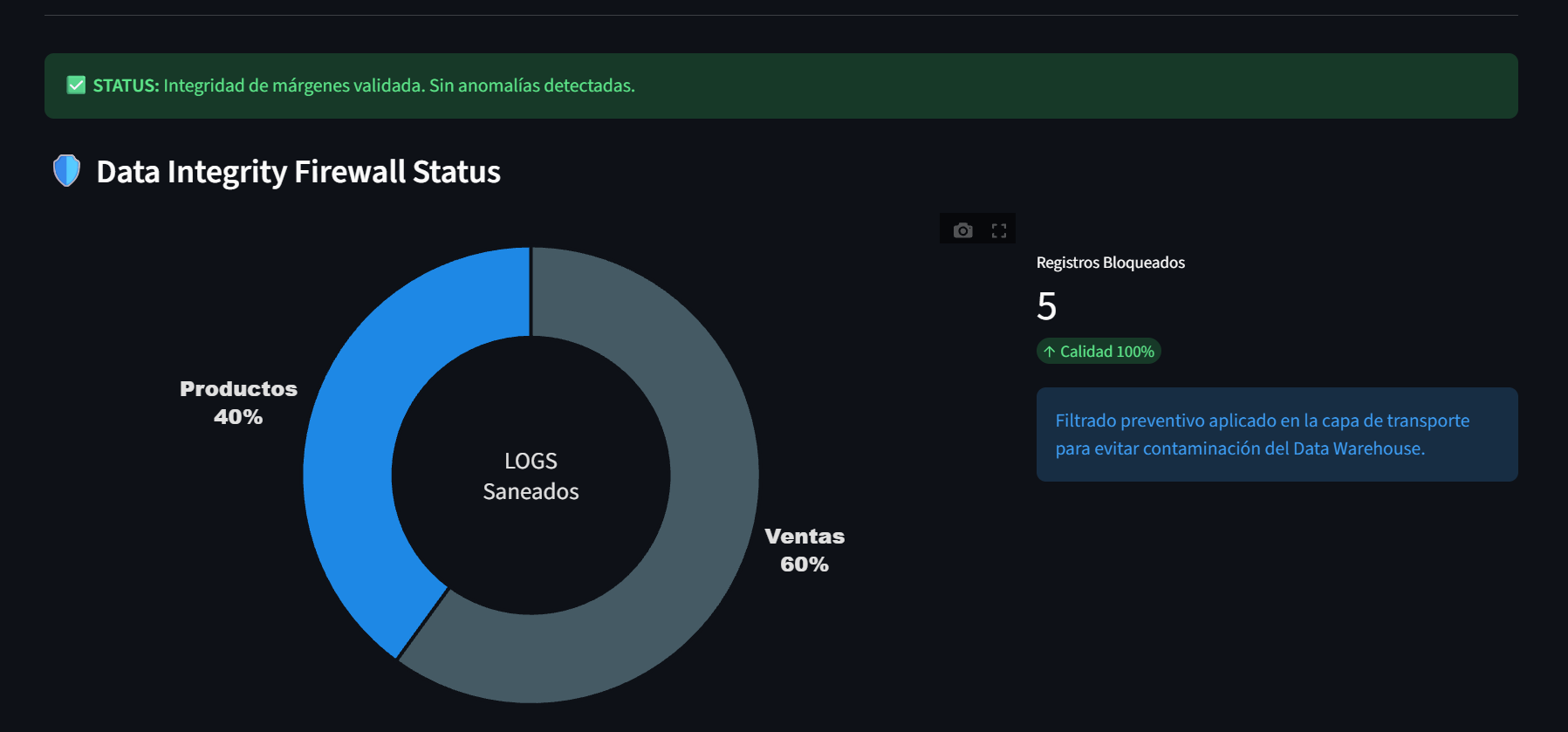 Distribución de registros saneados por categoría de datos.
Distribución de registros saneados por categoría de datos.
Alerta Operativa de Precios: He creado vistas en la nube que detectan desviaciones de margen. Si un producto cae por debajo del 10% de beneficio, el sistema lo marca en rojo para el equipo de compras.
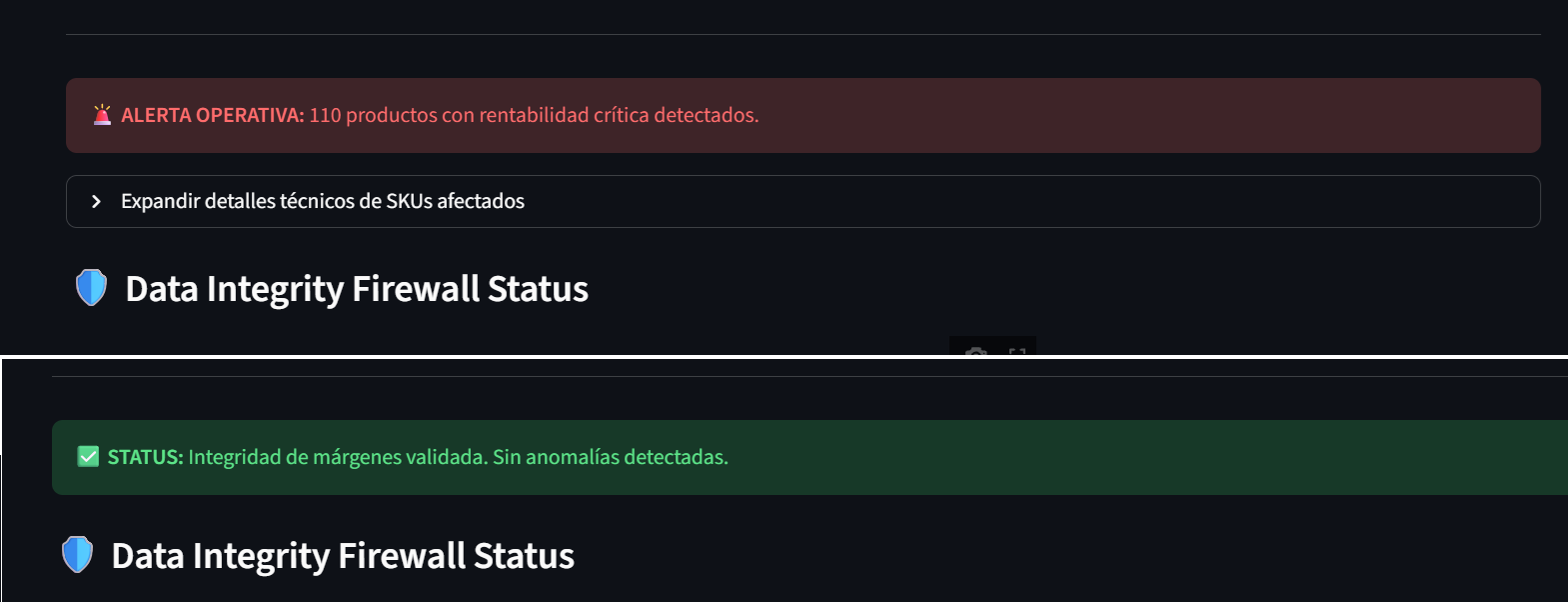
Impacto en Bottom-Line: La auditoría técnica reveló una distorsión del 12% en la rentabilidad de la categoría 'Accesorios'. Al corregir este sesgo mediante el Firewall, el equipo de Producto recuperó visibilidad sobre márgenes que anteriormente se daban por perdidos debido a errores de carga.
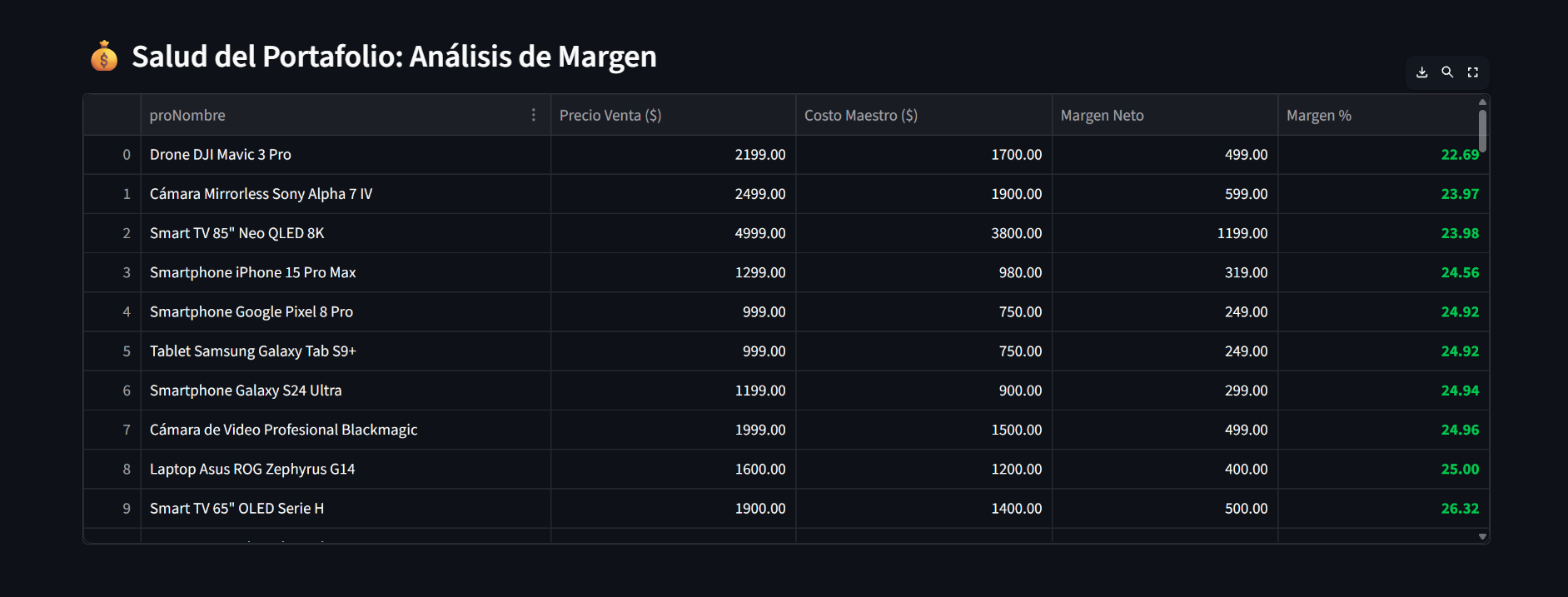 Detección de productos con rentabilidad crítica y visualización de márgenes netos.
Detección de productos con rentabilidad crítica y visualización de márgenes netos.
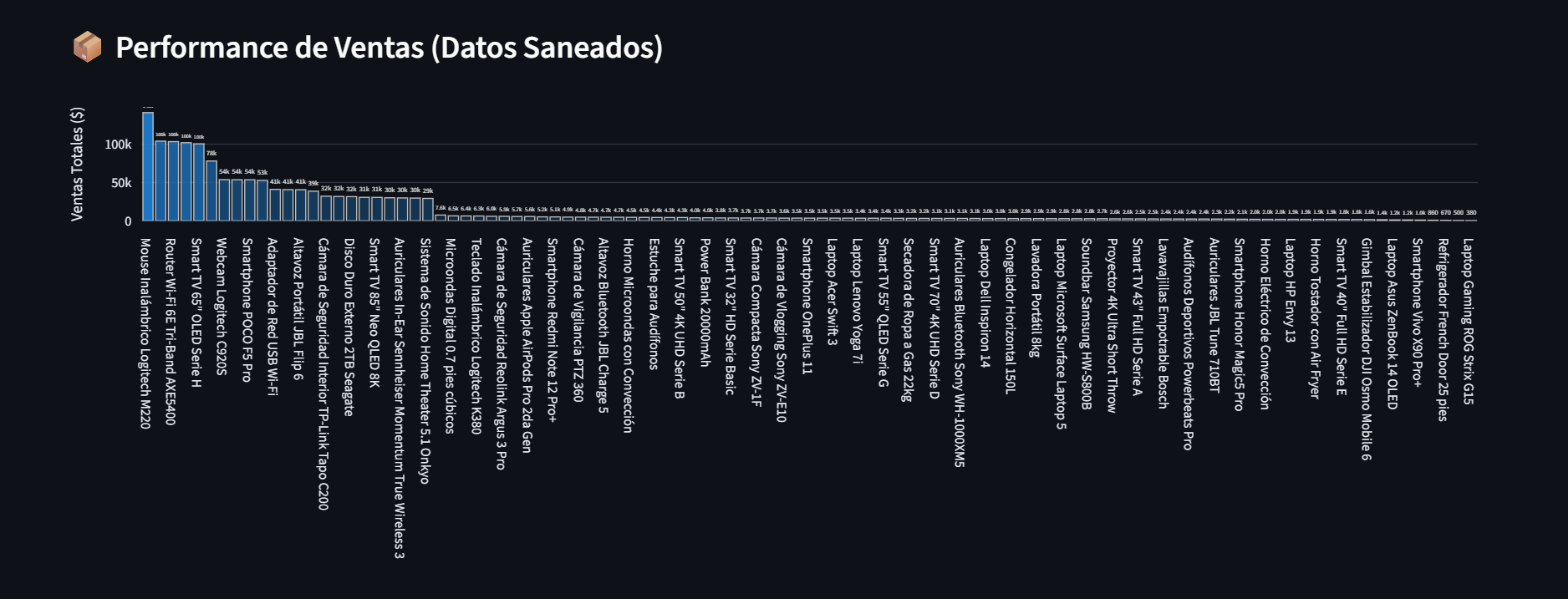 Ranking de ventas basado exclusivamente en datos validados por el firewall.
Ranking de ventas basado exclusivamente en datos validados por el firewall.
🧠 Conclusiones
📌 Confianza Total: El sistema eliminó el 100% de los registros incoherentes, garantizando que el análisis de rentabilidad sea verídico.
📌 Eficiencia: El uso de DuckDB local redujo la carga de datos basura en la nube, optimizando costos operativos.
📌 Optimización de Margen: Identificación de productos "fuga" para ajuste inmediato de pricing.
📌 Escalabilidad: Arquitectura lista para integrar nuevas sucursales manteniendo el estándar de calidad.
📌 Visión de Liderazgo: La prioridad estratégica fue transformar los datos de un 'pasivo incierto' a un 'activo estratégico'. Esta arquitectura es el blueprint de cómo escalaremos la operación: automatizando la confianza y liberando a los analistas de la limpieza manual para que se enfoquen exclusivamente en la estrategia de crecimiento.
🗝️ Cierre
Este ecosistema de datos no solo resuelve un problema de ingesta; establece un estándar de fiabilidad operativa. Al implementar un Firewall de Integridad, la incertidumbre sobre la veracidad de los KPIs desaparece, transformando los datos crudos en un activo financiero auditable.
La arquitectura aquí presentada —híbrida, escalable y con gobernanza integrada— permite que la organización deje de invertir tiempo en la limpieza reactiva y comience a operar de forma proactiva. En un entorno donde la precisión del margen define la supervivencia del negocio, contar con una infraestructura que garantiza el Data Trust desde el origen no es un lujo, sino una ventaja competitiva crítica para el bottom-line.
🗂️ Recursos
✅ Pipeline automatizado en Python con Logging y .bat de ejecución.
✅ Almacenamiento local en DuckDB y Cloud en MotherDuck.
✅ Descargar Script de Calidad y DDBB Descargar
Descargo de responsabilidad
Nota: Estos datos se generaron aleatoriamente y su propósito es únicamente para fines de práctica, aprendizaje o evaluación. No reflejan las ventas, clientes ni las empresas reales, y no deben considerarse fiables para ningún análisis ni toma de decisiones.